Machine learning was first defined by computer scientist Arthur Samuel in late 1950s as “a field of study that gives computers the ability to learn without being explicitly programmed.” It differs from traditional programming in several ways.
In traditional programming, inputs are system characteristics and a program of rules that govern that system; the output is the system’s performance. In machine learning, inputs are data that includes both the system characteristics and performance for many system variations, and output is a program that can predict the system output based on the system characteristics. As a result, in traditional programming the program grows by fine-tuning the rules while in machine learning the program fine-tunes with additional data. In the scope of Computer Aided Engineering (CAE), traditional programs are referred to as physics-based simulations and machine learning models as data-based predictive models.
Similar to how physics-based simulation programs are categorized with respect to the physics they are solving for, machine learning algorithms are also categorized with respect to objectives and data characteristics. In general, machine learning algorithms are classified as supervised or unsupervised.
When the goal is known, and the data has labels, that is considered supervised learning. Examples of this include predicting house prices based on house sizes, part stress based on part dimensions, or bearing status (normal or irregular) based on accelerometer data.
In unsupervised learning, the goal is to find patterns in the data, and data does not have labels. Examples of this include predicting credit fraud given credit history or predicting anomalies in bearings given accelerometer data. Supervised learning can be of regression or classification type whereas unsupervised learning is of clustering type.
At Altair, we have been using regression type machine learning algorithms for design exploration and optimization for over 30 years. Our recent acquisition of the Carriots Internet of Things (IoT) platform has expanded the scope of in-house expertise in machine learning. This article addresses engineering applications that are successfully employing the use of machine learning.
Predictive Modeling and Prescriptive Analytics of CAE or Test Data
In the first application, Altair Multidisciplinary Design Optimization Director (MDOD) uses simulation data for supervised learning. To meet today’s demanding requirements for product performance and its time-to-market, the use of Multidisciplinary Design Optimization (MDO) has become a need.
Those familiar with MDO applications are well aware that setting up and solving MDO problems can be labor intensive and computationally expensive, especially if the application is large-scale such as an automotive Body-in-White (BIW) design. Altair’s MDOD is an environment developed to break these barriers for utilizing MDO in engineering applications. Its model-centric environment utilizes automated model linking and a rich visualization for ease of setup and review. It also employs efficient and extensible sampling methods that are conducive to machine learning. For optimization, MDOD leverages efficient machine learning based on global search methods for computational effort reduction.
A case in point highlights the predictive modeling and prescriptive studies that were performed for a fabric softener bottle redesign to sustain new transportation conditions. Unilever Corporation needed to increase the load carrying capacity of a fabric softener bottle without adding to the bottle weight. Altair HyperWorks™ was used to parametrize the design features.
A Design of Experiments (DOE) study was used for feature reduction, from which a predictive model was created. Finally, a prescriptive study was conducted using this model. The resulting design had 20% more load carrying capacity, while at the same time achieving mass savings of 5%.
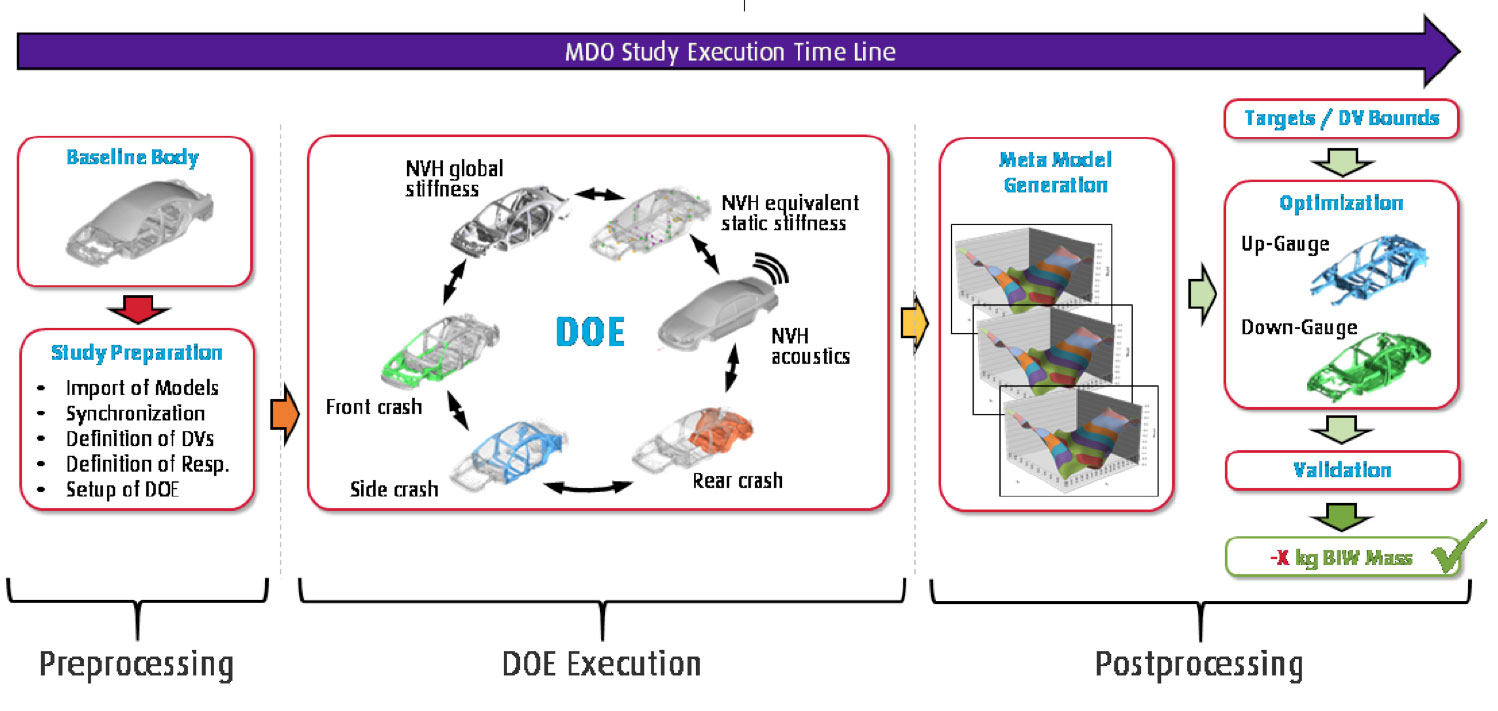 Altair Multi-disciplinary Design Optimization Director (MDOD) Process
Altair Multi-disciplinary Design Optimization Director (MDOD) Process
Merging Physics-Based Simulations with Data-Driven Predictive Models
In a research project with one of Altair’s major customers, machine learning methods were successfully employed to create a concept design for a reinforcement bracket subjected to crash loads. Concept design methodologies using topology optimization often have difficulties when exploring highly nonlinear events such as crash applications. In this particular application, we had to avoid any folding modes after the crash event.
To be able to include this key performance indicator (KPI) as a response in the optimization study, the design space was sampled first. Clustering was then used to group them with respect to their folding mode. Once the clusters were known, the consecutive designs could be classified. Using regressions and classification, the design was optimized to achieve the desirable folding mode and highest energy absorption.
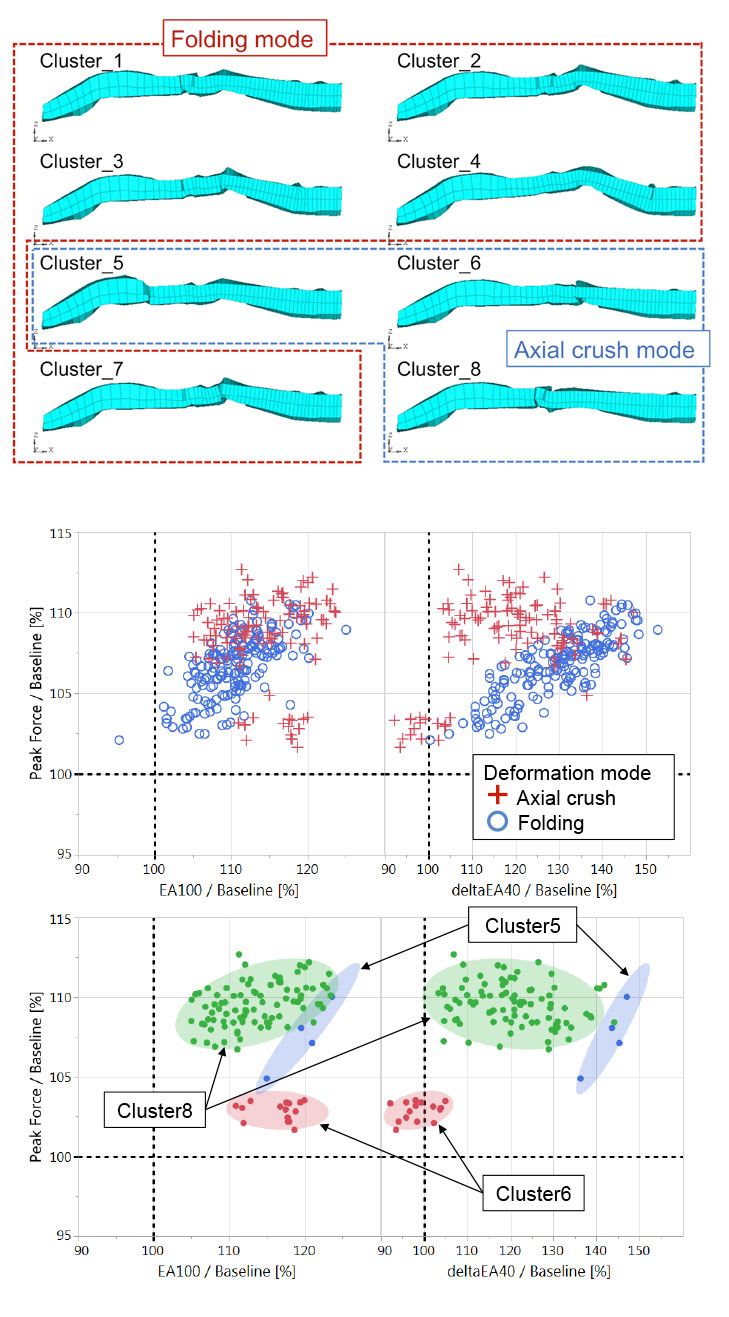 Clustering Analysis of Design Data for Folding Mode
Clustering Analysis of Design Data for Folding Mode
Merging Historical and Real-Time Data
Aircraft engines go through a number of cycles of demanding and varying conditions. To avoid catastrophic failures, they require a very thorough maintenance program. Maintenance of engines is costly due to engine downtime and the time and labor involved.
The engines are equipped with a number of sensors measuring temperatures and pressures at various locations as well as other important measures such as fuelto-air ratio and fan speed. Using machine learning algorithms, this sensor data can be used to make predictions of engine health based on the conditions it has been subjected to through its lifecycle.
The NASA Prognostics Center of Excellence (PCoE) at Ames Research Center provides two sets of sensor data to be used for model training and testing (https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/). Included in the training data set are 21 sensors’ data from 100 engines that ran to failure. In the testing data set, the engines remain in operation. The objective is to predict the Remaining Useful Lifecycles (RUL) before the engines in the test set fail.
To solve this problem, the RUL was defined and computed. The data was then reviewed and cleaned. Most importantly, the characteristics of the data such as important sensors were identified. An automated predictive modeling technique was used to come up with the best model based on its cross-validation coefficient of determination, or R2. This model was then employed to predict the RUL of the engines in operation.
As demonstrated by the results in the table, the predictions for engines with sensor data for 100+ cycles were on-target. Since the engines on average go to 200 cycles, the predictions become accurate halfway during the total lifecycles. For the engines with less data, with no patterns emerging, the predictions will have larger confidence intervals.
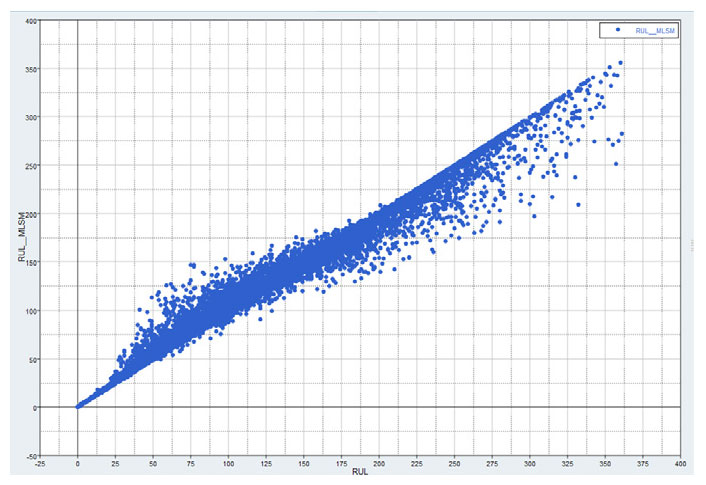 Actual vs Predicted Engine RUL
Actual vs Predicted Engine RUL
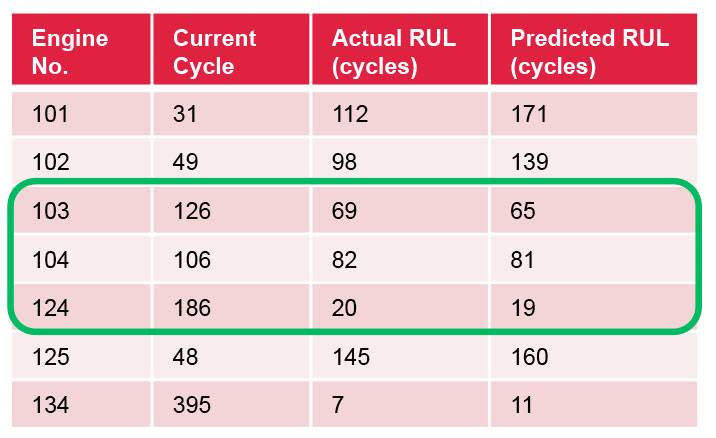 Actual vs Predicted RUL for Engines in Operation
Actual vs Predicted RUL for Engines in Operation
An example of an application for unsupervised machine learning is related to bearings – a critical component in most industries. PCoE provides bearing accelerometer sensor data for four bearings at a sampling rate of 20kHz, resulting in sampling every 10 minutes for a duration of 1 second for 9 days. This totals 20 million records. The first sampling corresponds to the new bearing and is used as a reference for anomaly detection of the bearing as it ages.
In this project, the objective is to recognize these anomalies as soon as they occur, before they lead to irreversible issues such as part failures. In the machine learning process, first Principle Component Analysis (PCA) is used for feature reduction, then the samples are correlated to the healthy sample. Finally, the anomaly is detected using a threshold for correlation drop and value.
So far, a supervised regression problem (engine RUL prediction) and an unsupervised machine learning problem (bearing anomaly detection) have been covered. Lastly, a supervised classification problem example based on an APS Failure at Scania Trucks Data Set from the UCI Machine Learning Repository will be reviewed.
The data is provided by Scania Trucks, but attribute labels have been changed to disguise the data. In this problem the objective was to minimize the maintenance costs of the air pressure systems (APS) in trucks. Maintenance was required to avoid a failure while trucks were in operation. As it is a costly procedure, on the one hand, it was desirable to perform maintenance only when needed. On the other, repair costs associated with a failure would be significantly higher. If the predictive model failed to predict a maintenance (false negative), the truck would fail during operation and it would cost 500 units to repair. If the predictive model showed a need for maintenance but in fact it was not needed (false positive), it would waste 10 units.
This data set has values for 171 attributes used in predicting whether maintenance was needed or not. The training set contained 60,000 rows of which 59,000 belonged to the negative (no maintenance required) class and 1,000 to the positive (maintenance required) class. The test set contained 16,000 examples that needed to be classified as negative or positive.
The first step in data-based modeling is to review the data for missing values and errors. Th is particular data had some attributes missing up to 82% of values. This could be due to lack of time to measure all attributes in between operations. This also meant that attributes with such high amounts of missing data would be the ones ignored by employees as not critical. As a result, eight attributes that have more than 50% missing values have been removed.
For other missing values, median imputation was used. With the remaining data, PCA for feature reduction was conducted on the remaining 162 attributes. It was found that 99% of variance in the data was explained by the first 110 principle components. Weights were allocated to classes for class imbalance in the data.
The resulting predictive model cost for this dataset was only 10,710 units, with 671 false positives and 8 false negatives. This quality is one of the best publicly reported in the literature.
Machine learning is not a new concept; it has been around since the 1960s. However, all the elements required for machine learning have come together only recently. Access to more bandwidth to transfer data over the internet, affordable data storage, and increasingly powerful computational resources is now widely available. Most importantly, universal accessibility to robust algorithms democratizes the use of machine learning. With the growth of IIoT and access to field data, the synergy between design and operation can easily be created and leveraged for better products. As engineers, our job is to identify the applications that can benefit from the use of machine learning and develop easy-to-use processes for them. The Altair MDO Director is a good example for this. It simplifies the creation and collection of data from different sources, it creates predictive models using machine learning and uses these to find optimal designs for an MDO problem, all done in an environment with an intuitive user interface.
There are many other engineering applications of machine learning. For more information please visit www.altair.com/machine-learning/
Dr. Fatma Kocer-Poyraz is Vice President, Business Development Design Exploration, Altair.
By Dr. Fatma Kocer-Poyraz